基数排序(Radix Sort)
基数排序
一、概论
基数排序(Radix sort)是一种非比较型整数排序算法,也是桶排序的延续。
二、设计与实现
①基数排序的实现逻辑:
1.将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。 2.从最低位开始,依次进行一次排序。 3.这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
②性能分析:
时间复杂度:O(k*n) 空间复杂度:O(k+n) 稳定性:稳定 可移植性:较强
③基数排序本身不难理解,难点在于如何正确且巧妙地将其实现。
我们先实现其核心部分(为了使排序具有可复用性,我们将使用类模板来实现基数排序):
for (int i = 0; i < begdig; i++) //0
{
auto result = creatResult(inarr); //1
std::array<int, 10> countArr{ 0 }; //2
for (auto& outone : inarr) //3
{
++countArr[outone / digit % 10];
}
for (int i = 1; i < countArr.size(); i++) //4
{
countArr[i] += countArr[i - 1];
}
for (int i = inarr.size() - 1; i >= 0; --i){ //5
result[countArr[inarr[i] / digit % 10] - 1] = inarr[i];
--countArr[inarr[i] / digit % 10];
}
inarr = result; //6
digit *= 10; //0
}
现在我们来解释一下上述代码:
0.digit指的是我们目前所在循环计算的位数,默认以个位开始计算;
0.begdig记录着最高的位数,也是控制我们外层循环何时退出的条件。
1.result接收了creatResult函数的返回值,这个函数的存在是为了提高代码的可复用、可移植性,因为我们不仅仅实现原始数组的基数排序,所以我们将根据传入排序的类型来判断我们使用的result将是什么类型,注意语句使用了auto,auto关键字将大大减少我们代码的维护难度。
2.countArr数组将作为桶记录我们分别将多少数“扔”进了对应基数的桶内。
3.第一个循环,我们将传入的数组的每个元素进行基数计算并“扔”进相应的桶内。
4.对桶内的元素进行内部统计合,目的在于为接下来排序中的相应元素留出足够的空间。比如,如果我们的countArr[0]=2、countArr[1]=1、countArr[2]=2,那么在统计合的操作过后它们对应的数值分别成为了2、3、5,那么当我们在接下来排序的过程中,当我们计算出的基数为2时,我们将会将其放到新数组下标为4的地方,从而为基数为0,1以及同样为2的元素预留出足够的空间去摆放(图1 统计合的理解)。
**
图1 统计合的理解
 **
5.这一步就很好理解了,就是将对应的元素根据基数大小放入对应的位置,但是不要忘了在放置元素后把它从桶中取出来(为什么不是先取出来再防止呢?如上一条代码的解释所说,元素相对应桶的值同时还承担着其前面元素位置的信息,更好理解的方法就是先找到位置再取出元素)。
**
5.这一步就很好理解了,就是将对应的元素根据基数大小放入对应的位置,但是不要忘了在放置元素后把它从桶中取出来(为什么不是先取出来再防止呢?如上一条代码的解释所说,元素相对应桶的值同时还承担着其前面元素位置的信息,更好理解的方法就是先找到位置再取出元素)。
6.这一步利用系统提供的std::vector默认复制赋值运算符重载来更新我们的答案数组,然后进入新的循环。
④完全实现基数排序
这里说明一下,为了方便后续自己复用,我们使用函数模板实现了三个版本的 基数排序(字符串的单独实现),并且将它们封装到一个类中(为什么不实现为类模板,之后会提到这个问题)。
class MySort
{
private:
int size{};
std::vector<int> newVector;
public:
template<typename T>
void getSize(T& inarr) const;
template<typename T> //针对vector与array的
void Radix_Sort(T& inarr) const;
template<typename T> //针对原始数组的模板
void Radix_Sort(T* inarr, int sizeit);
template<typename T>
void show(T& inarr) const;
template<typename T>
T creatResult(T& inarr) const;
MySort() = default;
template<typename T>
void setSize(T* inarr, int sizeit)
{
this->size = sizeit;
for (int i = 0; i < size; i++)
newVector.emplace_back(*(inarr + i));
}
template<typename T>
void show(T* inarr) const
{
for (int i = 0; i < size; i++)
std::cout << *(inarr + i) << " ";
std::cout << "\n";
}
template<typename T>
void re_Back(T* inarr) const
{
for (int i = 0; i < newVector.size(); i++)
inarr[i] = newVector.at(i);
}
template<typename T>
void show() const
{
for (auto& i : newVector)
std::cout << i << " ";
std::cout << "\n";
}
template<> //vector的特化
std::vector<int> creatResult<std::vector<int>>(std::vector<int>& inarr) const
{
std::vector<int> result(inarr.size());
return result;
}
};
template<typename T>
void MySort::Radix_Sort(T* inarr, int sizeit)
{
setSize(inarr, sizeit);
if (!(size == 0))
{
T maxone{};
maxone = *std::max_element(newVector.begin(), newVector.end()); //找到最大元素
int digit{ 1 };
int begdig{ 1 };
while (maxone >= 10) //计算最高位数
{
maxone /= 10;
++begdig;
}
for (int i = 0; i < begdig; i++)
{
std::vector result(size, 0);
std::array<int, 10> countArr{ 0 };
for (auto& outone : newVector)
{
++countArr[outone / digit % 10];
}
for (int i = 1; i < countArr.size(); i++)
{
countArr[i] += countArr[i - 1];
}
for (int i = size - 1; i >= 0; --i)
{
result[countArr[newVector[i] / digit % 10] - 1] = newVector[i];
--countArr[newVector[i] / digit % 10];
}
newVector = result;
digit *= 10;
}
}
else
{
std::cout << "输入数组为空,请检查数组。\n";
}
re_Back(inarr);
}
template<typename T>
T MySort::creatResult(T& inarr) const
{
T result{ static_cast<int>(inarr.size()) };
return result;
}
template <typename T>
void MySort::Radix_Sort(T& inarr) const
{
if (!(inarr.size() == 0))
{
int maxone{};
maxone = *std::max_element(inarr.begin(), inarr.end()); //找到最大元素
int digit{ 1 };
int begdig{ 1 };
while (maxone >= 10) //计算最高位数
{
maxone /= 10;
++begdig;
}
for (int i = 0; i < begdig; i++)
{
auto result = creatResult(inarr);
std::array<int, 10> countArr{ 0 };
for (auto& outone : inarr)
{
++countArr[outone / digit % 10];
}
for (int i = 1; i < countArr.size(); i++)
{
countArr[i] += countArr[i - 1];
}
for (int i = inarr.size() - 1; i >= 0; --i)
{
result[countArr[inarr[i] / digit % 10] - 1] = inarr[i];
--countArr[inarr[i] / digit % 10];
}
inarr = result;
digit *= 10;
}
}
else
{
std::cout << "输入数组为空,请检查数组。\n";
}
}
template <typename T>
void MySort::show(T& inarr) const
{
for (auto& outone : inarr)
std::cout << outone << " ";
std::cout << "\n";
}
最后对单独对原始数组的特化进行一些解释,因为原始数组不能提供如array,vector等模板类有的成员函数,所以我们在实现排序时通过重新创建一个新的vector也就是类中的newVector,将原始数组通过setSize函数将其复制到newVector中,使得我们的排序核心代码完全不需要改变就可以直接复用,最后别忘了将排序好的vector数组复制回原始数组中(我承认还有许多地方是可以优化的,但是由于时间原因优化的工作放到实验结束)。
⑤由于题目提到要实现文件的字符串进行首字母的排序,我们单独实现(这时候就体现了我们代码可移植性强的特点了)
class my_sortof_str{
private:
std::vector<std::string> strarr;
std::vector<char> firstChar;
public:
void outFileContain(std::ifstream& outStream){
if (outStream.is_open()){
std::cout << "文件打开成功" << std::endl;
std::string sample;
while (outStream >> sample){
strarr.emplace_back(sample);
firstChar.emplace_back(sample[0]);
}
}
}
void show() const{
for (auto& str : strarr)
std::cout << str << std::endl;
}
int returnMaxOne(){
int count = strarr.size();
}
void Radix_Sort(){
if (!(strarr.size() == 0)){
int maxone{};
maxone = *std::max_element(firstChar.begin(), firstChar.end()); //找到最大元素
int digit{ 1 };
int begdig{ 1 };
while (maxone >= 10){ //计算最高位数
maxone /= 10;
++begdig;
}
for (int i = 0; i < begdig; i++){
auto result = std::vector<std::string>(strarr.size());
std::array<int, 10> countArr{ 0 };
for (auto& outone : strarr){
++countArr[static_cast<int>(outone[0]) / digit % 10];
}
for (int i = 1; i < countArr.size(); i++){
countArr[i] += countArr[i - 1];
}
for (int i = strarr.size() - 1; i >= 0; --i){
result[countArr[strarr[i][0] / digit % 10] - 1] = strarr[i];
--countArr[strarr[i][0] / digit % 10];
}
strarr = result;
digit *= 10;
}
}
else{
std::cout << "输入数组为空,请检查数组。\n";
}
}
};
我们来解释一下可移植性强的特点,我们知道,每个字符都能对应这唯一的ASCII或者Unicode码,两者都是 字符——整数 的形式,那么我们在获取字符串的时候,outFileContain就帮助我们按空格取出了每一个子字符串以及每个子字符串的首字母,这样我们在进行排序操作中只需要在每个strarr[i](字符串数组)中添加一个strarr[i][0](子字符串的首字母)去比较排序即可,大大减小了代码的维护难度。
三、系统测试
关于原始数组、std::vector和std::array类的基数排序测试,我们只需要建立一个类,通过类中提供的函数模板接口去实现基数排序,并通过类的成员函数show去输出我们排序好的数组。
MySort intSort_1;
int textvector_1[] = { 10, 15, 18, 16, 26, 3, 7, 5, 9, 102 };
std::vector textvector_2{ 10, 15, 18, 16, 26, 3, 7, 5, 9, 102 };
std::array textvector_3 = { 10, 15, 18, 16, 26, 3, 7, 5, 9, 102 };
std::span textvector_4{ textvector_1,10 };
intSort_1.Radix_Sort(textvector_1, sizeof(textvector_1) / 4);
intSort_1.show(textvector_1);
intSort_1.Radix_Sort(textvector_2);
intSort_1.show(textvector_2);
intSort_1.Radix_Sort(textvector_3);
intSort_1.show(textvector_3);
输出(图2 int数组排序输出展示):
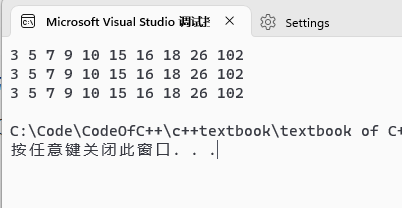
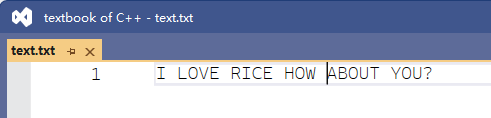
图2 int数组排序输出展示 关于字符串的测试(图3 text.txt文件展示),我们将文件打开后就可以实例化我们的字符串基数排序类,而后通过提供的各个接口将文档中的字符串取出并进行排序如果需要将新的字符串写入,那么清除文档中的内容然后将新字符串一一写入文件即可(别忘了子字符串之间以空格为间隔):
图3 text.txt文件展示
std::ifstream myStream("text.txt", std::ios::binary);
my_sortof_str gotU;
gotU.outFileContain(myStream);
gotU.show();
printf("\n");
gotU.Radix_Sort();
gotU.show();
myStream.close();
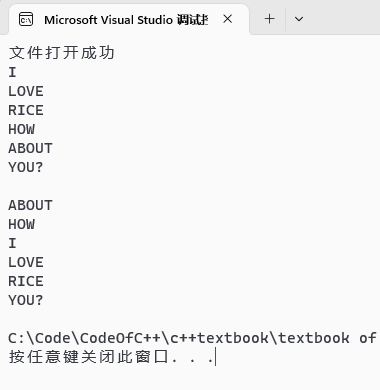
输出(图4 字符串排序输出展示):
图4 字符串排序输出展示
四、评价与结论
具体实验中遇到如下几个问题:
1.应该选用类模板还是封装的函数模板?
刚开始编写时我确实是写的类模板,但是在之后的思考中我发现,如果使用类模板,那么每个类型都需要单独实例化一个对象来做接口,这在使用时会造成很大的麻烦,所以最终还是决定使用一个类去封装函数模板。但之后又意识到一个问题,当vector以及array大小不同时,无法使用同一个函数模板编译,所以我为什么不直接使用函数重载呢?所以总的来说,上述代码不仅可以说是无意义的,甚至是差劲的。